Big Data for Public Policy¶
Scraping the Internet to Collect Data¶
Malka Guillot¶
ETH Zürich | 860-0033-00L¶
Outline¶
- Introduction
- HTML: scraping and parsing
- Web APIs
Topics of this coding session
- Gathering (unstructured) web data and transforming it into structureddata (“web scraping”).
- Accessing data on the web: APIs.
Intro¶
General interest references:¶
- Edelman, Benjamin. 2012. "Using Internet Data for Economic Research." Journal of Economic Perspectives, 26 (2): 189-206.
- Cavallo, Alberto, and Roberto Rigobon. 2016. "The Billion Prices Project: Using Online Prices for Measurement and Research." Journal of Economic Perspectives, 30 (2): 151-78.
Coding resources:¶
- Python's requests & Beautiful Soup libraries (for web scraping & APIs)
- Ryan Mitchell, Web Scraping with Python, O'Reilly Media, 2018

What is Web Scraping?¶
- Process of gathering information from the Internet
- structure or unstructured info
- Involves automation
Challenges of Web Scraping¶
- Variety. Every website is different.
- Durability. Websites constantly change.
Points to keep in mind:¶
- It may or may not be legal
- Loop at websites’ terms of service and robots.txt files
- Webscraping is tedious and frustrating
Motivation¶
Publication of crawling papers by year
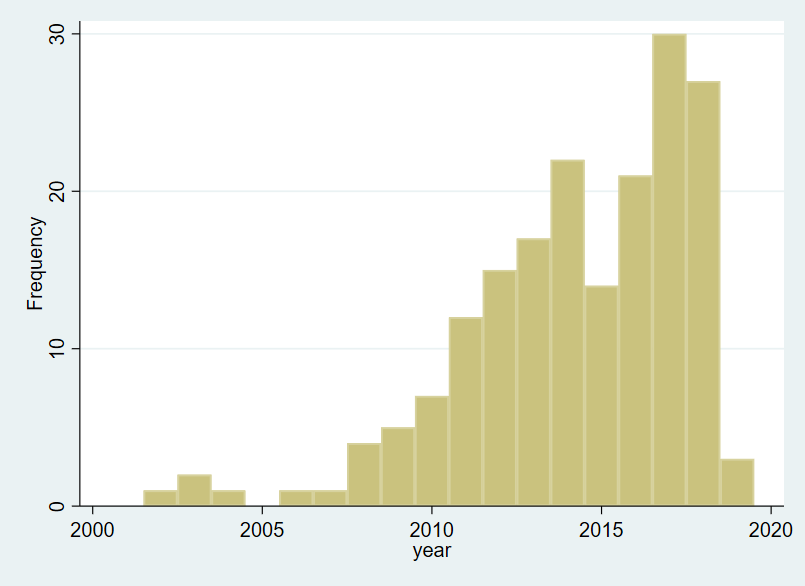
Source: Claussen, Jörg and Peukert, Christian, Obtaining Data from the Internet: A Guide to Data Crawling in Management Research (June 2019).
Example of data¶
- Online markets: housing, job, goods
- Social media: Twitter, Facebook, Wechat, newspaper text
- Historical data using the internet Archives
Getting started: Things to consider before you begin¶
- Send an email to try to get the data directly
- Search if somebody has already faced the same or a similar problem.
- Does the site or service provide an API that you can access directly?
- Is the website only online for a limited time? Do you want an original snapshot as a backup? Is it more convenient to filter your data offline?
- Which
python packageis needed?
Most important python library for data collection¶
- Standard:
RequestsBeautiful Soup
- More advanced
ScrapydocumentationSelenium
$+$ installing the package:
pip install BeautifulSoup4
Load packages¶
# Import packages + set options
from IPython.display import display
import json
import pandas as pd
pd.options.display.max_columns = None # Display all columns of a dataframe
pd.options.display.max_rows = 700
from pprint import pprint
import re
Data communication for the World Wide Web¶
HTTP protocol= way of communication between the client (browser) and the web server- no encryption $\rightarrow$ not safe
HTTPS protocol= S for secured
$\Rightarrow $ works by doing Requests and Responses
Static vs. dynamic websites¶
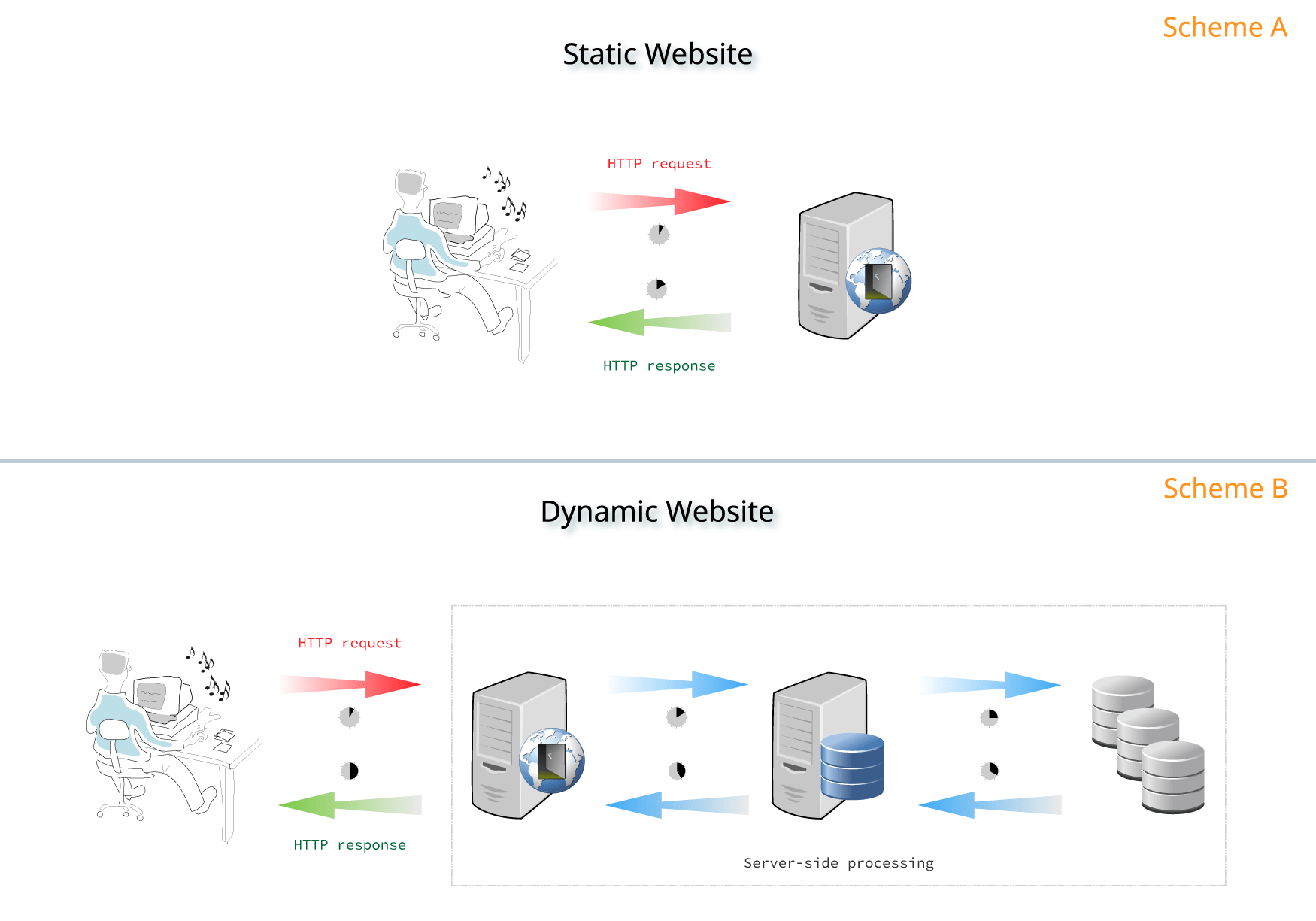
Notes:
- Static Websites: the server that hosts the site sends back HTML documents that already contain all the data you’ll get to see as a user.
Request and Response¶
all interactions between a client and a web server are split into a request and a response:
Requestscontain relevant data regarding your request call:- base URL [ More on this for API: the endpoint, the method used, the headers, and so on.]
Responsescontain relevant data returned by the server:- the data or content, the status code, and the headers.
import requests
url='https://ballotpedia.org/List_of_current_members_of_the_U.S._Congress'
response = requests.get(url)
Request's attributes¶
request = response.request
print('request: ',request)
print('-----')
print('url: ',request.url)
print('-----')
print('path_url: ', request.path_url)
print('-----')
print('Method: ', request.method)
print('-----')
print('Method: ', request.headers)
Response's attributes¶
.textreturns the response contents in Unicode format.contentreturns the response contents in bytes.
print('', response)
print('-----')
print('Text:', response.text[:50])
print('-----')
print('Status_code:', response.status_code)
print('-----')
print('hHeaders:', response.headers)
Status Codes¶
Important information: if your request was successful, if it’s missing data, if it’s missing credentials

Scraping & Parsing in Practice¶
STEPS:¶
- Inspect Your Data Source
- Scrape HTML Content From a Page
- Parse HTML Code With Beautiful Soup
Understanding URLs¶
- Base URL: https://ballotpedia.org/List_of_current_members_of_the_U.S._Congress
- More complex URL with query parameter https://ballotpedia.org/wiki/index.php?search=jerry
- query parameter=
p?search=jerry - can be used to crawl websites if you have a list of queries that you want to loop over (e.g. dates, localities...)
- query structure:
- Start:
? - Information: pieces of information constituting one query parameter are encoded in key-value pairs, where related keys and values are joined together by an equals sign (key=value).
- Separator:
&-> if multiple query parameters
- Start:
- query parameter=
Other example of URL: https://opendata.swiss/en/dataset?political_level=commune&q=health.
Your turn
Try to change the search and selection parameters and observe how that affects your URL.
Next, try to change the values directly in your URL. See what happens when you paste the following URL into your browser’s address bar:
Conclusion: When you explore URLs, you can get information on how to retrieve data from the website’s server.
Inspect the site: Using Developer Tools¶
We use the inspect function (right click) to access the underlying HTML interactively.
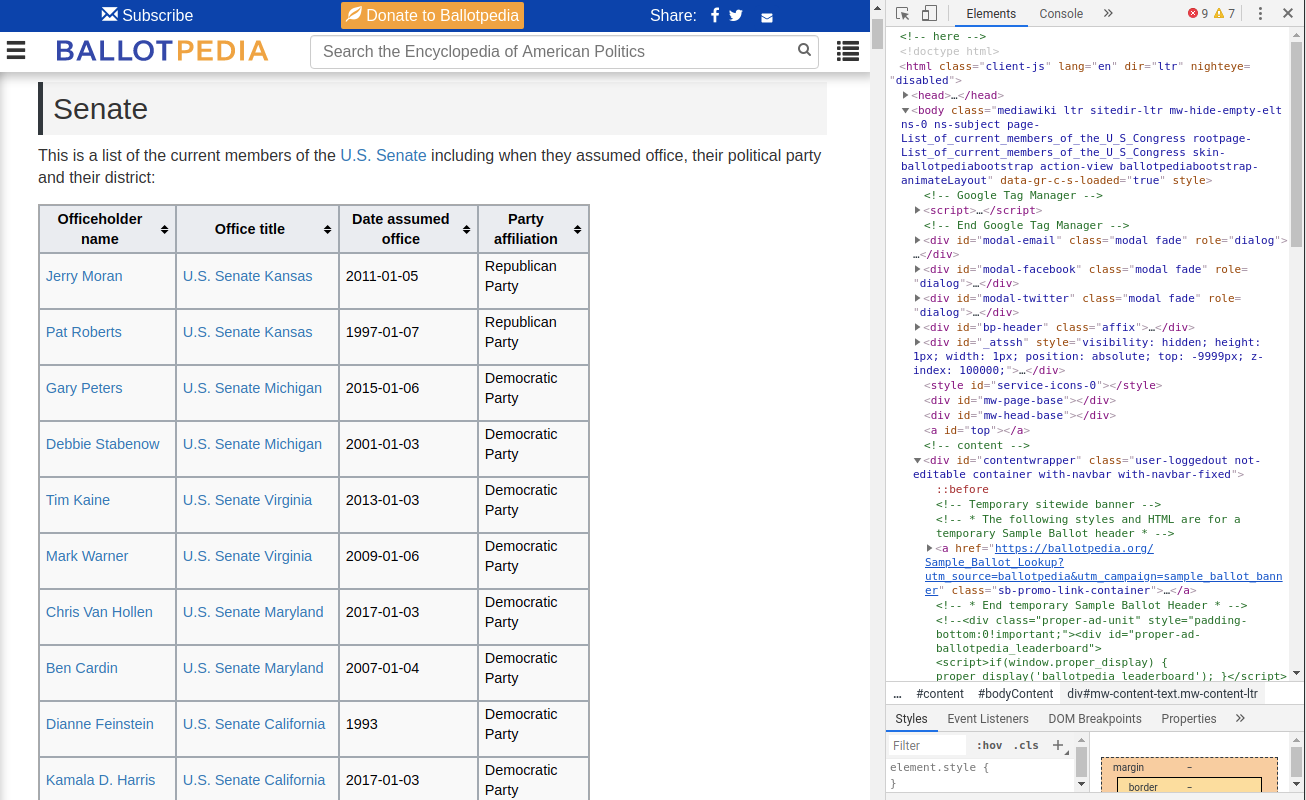
Developer tools¶
- Developer tools can help you understand the structure of a website
- I use it in firefox, but exists for most browsers
- Interactively explore the source html & the webpage
html is great but intricated $\Rightarrow$ sublimed by beautifulsoup
Step 2: Scrape HTML Content From a Page¶
import requests
url='https://ballotpedia.org/List_of_current_members_of_the_U.S._Congress'
response = requests.get(url)
html=response.text
html[:500]
html looks messy.
Using the prettify() function from BeautifulSoup helps
# Parse raw HTML
from bs4 import BeautifulSoup # package for parsing HTML
soup = BeautifulSoup(html, 'html.parser') # parse html of web page
print(soup.prettify()[:1000])
Step 3: Parse HTML Code With Beautiful Soup¶
Objectif: extract url of senators from the webpage to build a list of url that will be used for scraping info on senators
Find Elements by ID¶
In an HTML web page, every element can have an id attribute assigned.
Can be used to directly access the element.
balance=soup.find(id='Leadership_and_partisan_balance')
print(balance.prettify()[:500])
Your turn
Find the id & get the soup for the table entitled *List of current U.S. Senate members*.
officeholder_table=soup.find(id='officeholder-table')
print(officeholder_table.prettify()[:500])
Find Elements by HTML Class Name¶
Because the result is not unique find_all instead of find.
Lets' rely on the html structure to find the row of the table
thead= officeholder_table.find('thead')
thead
rows=officeholder_table.find_all('tr')
len(rows) # consistent: 100 members + headline
Let's try to get the url for one example row:¶
row=rows[1]
#row
tds=row.find_all('td')
tds[:4]
url= tds[1].find_all('a')
print('a list:', url)
print('its unique element', url[0])
print('url wanted', url[0]['href'] )
print('Text content', url[0].get_text())
Your turn
Use the code for 1 row in order to build a loop that gives a list of all of the wanted url.
list_url=[]
for row in rows[1:]:
tds=row.find_all('td')
url= tds[1].find_all('a')[0]['href']
list_url.append(url)
list_url[:10]
Your First Scraper¶
Then, the same logic can be implemented to get the info from the senators' page (e.g. https://ballotpedia.org/Jerry_Moran). The following code extracts info from the first 5 url from the list scraped above.
from bs4 import NavigableString, Tag
# the dataframe in which we will put the scraper's output
df_parsed=pd.DataFrame()
for url in list_url[:10]:
print('--------',url, '--------')
#1. Get the soup
response = requests.get(url)
html=response.text
soup = BeautifulSoup(html, 'html.parser') # parse html of web page
dic_text_by_header=dict()
#2. Extract info from the soup
# get all the text content between 2 header (h2)
for header in soup.find_all('h2')[0:len(soup.find_all('h2'))-1] :
# print('--------',header.get_text())
nextNode=header
# use the nextSibling method
while True:
nextNode=nextNode.nextSibling
if nextNode is None:
break
if isinstance(nextNode, Tag):
if nextNode.name == "h2":
break
#print(nextNode.get_text(strip=True).strip())
# The result is put in a dictionary as a value for key=corresponding header
dic_text_by_header[header.get_text()]=[nextNode.get_text(strip=True).strip()]
# put the dictionary into a dataframe
temp=pd.DataFrame.from_dict(dic_text_by_header)
# Concats the temporary dataframe with the global one
df_parsed=pd.concat([temp, df_parsed])
df_parsed.head()
Saving the DataFrame in a pickle format¶
pickle format
- Useful to store
pythonobjects - Well integrated in
pandas(usingto_pickleandread_pickle) - When the object is not a pandas Dataframe, use the
picklepackage
os package
-
os.getcwd(): fetchs the current path -
os.path.dirname(): go back to the parent directory -
os.path.join(): concatenates several paths
import os
parent_path=os.path.dirname(os.getcwd()) # os.getcwd() fetchs the current path,
data_path=os.path.join(parent_path, 'data')
df_parsed.to_pickle(os.path.join(data_path, 'df_senators.pickle'))
Going further¶
There are also dynamic websites: the server does not always send back HTML, but your browser also receive and interpret JavaScript code that you cannot retreive from the HTML. You receive JavaScript code that you cannot parse using beautiful soup but that you would need to execute like a browser does.
Solutions:
- Use
requests-html - Simulate a browser using selenium
Application Programming Interfaces (API)¶
What is an API?¶
Communication layer that allows different systems to talk to each other without having to understand exactly what each other does.
$\Rightarrow$ provide a to progammable access to data.
The website Programmable Web lists more than 225,353 API from sites as diverse as Google, Amazon, YouTube, the New York Times, del.icio.us, LinkedIn, and many others.

Source: Programmable Web
How Does an API Work?¶
- Relying on HTTP messages :
requestfor information or data,- the API returns a
responsewith what you requested
- Similar to visiting a website: you specify a URL and information is sent to your machine.
Better than webscraping if possible because:¶
- More stable than webpages
- No HTML but already structured data (e.g. in
json) - we focus on the APIs that use HTTP protocol

HTTP Methods¶
| HTTP Method | Description | Requests method |
|---|---|---|
| POST | Create a new resource. | requests.post() |
| GET | Read an existing resource. | requests.get() |
| PUT | Update an existing resource. | requests.put() |
| DELETE | Delete an existing resource. | requests.delete() |
Calling Your First API Using Python¶
Forecasts from the Carbon Intensity API (include CO2 emissions related to eletricity generation only).
See the API documentation

import requests
headers = {
'Accept': 'application/json'
}
# fetch (or get) data from the URL
requests.get('https://api.carbonintensity.org.uk', params={}, headers = headers)
response = requests.get('https://api.carbonintensity.org.uk', params={}, headers = headers)
print(response.text[:500])
Endpoints and Resources¶
- base URL: https://api.carbonintensity.org.uk
- Other examples: https://api.twitter.com; https://api.github.com
- very basic information about an API, not the real data.
- Extend the url with endpoint
- = a part of the URL that specifies what resource you want to fetch
- check the documentation to learn more about what endpoints are available
Using the intensity endpoint:¶
# Get Carbon Intensity data for current half hour
r = requests.get('https://api.carbonintensity.org.uk/intensity', params={}, headers = headers)
# Different outputs:
print("--- text ---")
pprint(r.text)
print("--- Content ---")
pprint(r.content)
print("--- JSON---")
pprint(r.json())
json
json= python dictionary- A great format for structured data
# json objects work as do any other dictionary in Python
json=r.json()
json['data']
# get the actual intensity value:
json['data'][0]['intensity']['actual']
Your turn
r = requests.get('https://api.carbonintensity.org.uk/intensity/factors', params={}, headers = headers)
pprint(r.json())
# Get Carbon Intensity data for current half hour for GB regions
r = requests.get('https://api.carbonintensity.org.uk/regional', params={}, headers = headers)
#pprint(r.json())
Query Parameters¶
- cf. slide on
url - used as filters you can send with your API request to further narrow down the responses.
# In the carbonintensity API, it works differently:
from_="2018-08-25T12:35Z"
to="2018-08-25T13:35Z"
r = requests.get('https://api.carbonintensity.org.uk/regional/intensity/{}/{}'.format(from_, to), params={}, headers = headers)
#pprint(r.json())
API Limitations¶
To prevent collection of huge amount of individual data, many APIs require you to obtain “credentials” or codes/passwords that identify you and determine which types of data you are allowed to access.
API Credentials¶
- Different methods/level of authentification exist
- API keys
- OAuth
Rate Limiting¶
- The credentials also define how often we are allowed to make requests for data.
- Be careful not to exceed the limits set by the API developers.
API Keys¶
- Most common level of authentication
- These keys are used to identify you as an API user or customer and to trace your use of the API.
- API keys are typically sent as a request header or as a query parameter.
Example of API key authentification using the nasa API!!!¶
endpoint = "https://api.nasa.gov/mars-photos/api/v1/rovers/perseverance/photos"
# Replace DEMO_KEY below with your own key if you generated one.
api_key = "DEMO_KEY"
# You can add the API key to your request by appending the api_key= query parameter:
query_params = {"api_key": api_key, "earth_date": "2021-02-27"}
response = requests.get(endpoint, params=query_params)
response
Authentification was a success!
response.json()
photos = response.json()["photos"]
print(f"Found {len(photos)} photos")
photos[50]["img_src"]

General remarks¶
- Start simple and expand your program incrementally.
- Keep it simple. Do not overengineer the problem.
- Do not repeat yourself. Code duplication implies bug reuse.
- Limit the number of iterations for test runs. Use print statements toinspect objects.
- Write tests to verify things work as intended.
- If the web page cannot be navigated easily or has hidden javascript, look into Selenium.
- If you scraper requires complex monitoring/validation procedures orthreading for performance, look into Python.
Class Survey¶
Please fill in this short survey about the class.